Structuring Forgetful Sessions: Data Minimization in Financial RAG
B2B Scenario Brief · Part 4 · AI engineering leads & infrastructure architects
Financial RAG prototypes often fail compliance review for a predictable reason: they persist what they retrieve. Embedding every trade row into a vector database creates a second ledger—one optimized for similarity search, not regulatory minimization.
Forgetful sessions invert the default: compute context per request, stream the answer, discard the portfolio payload. No vector memory bank of client transactions on the inference path.
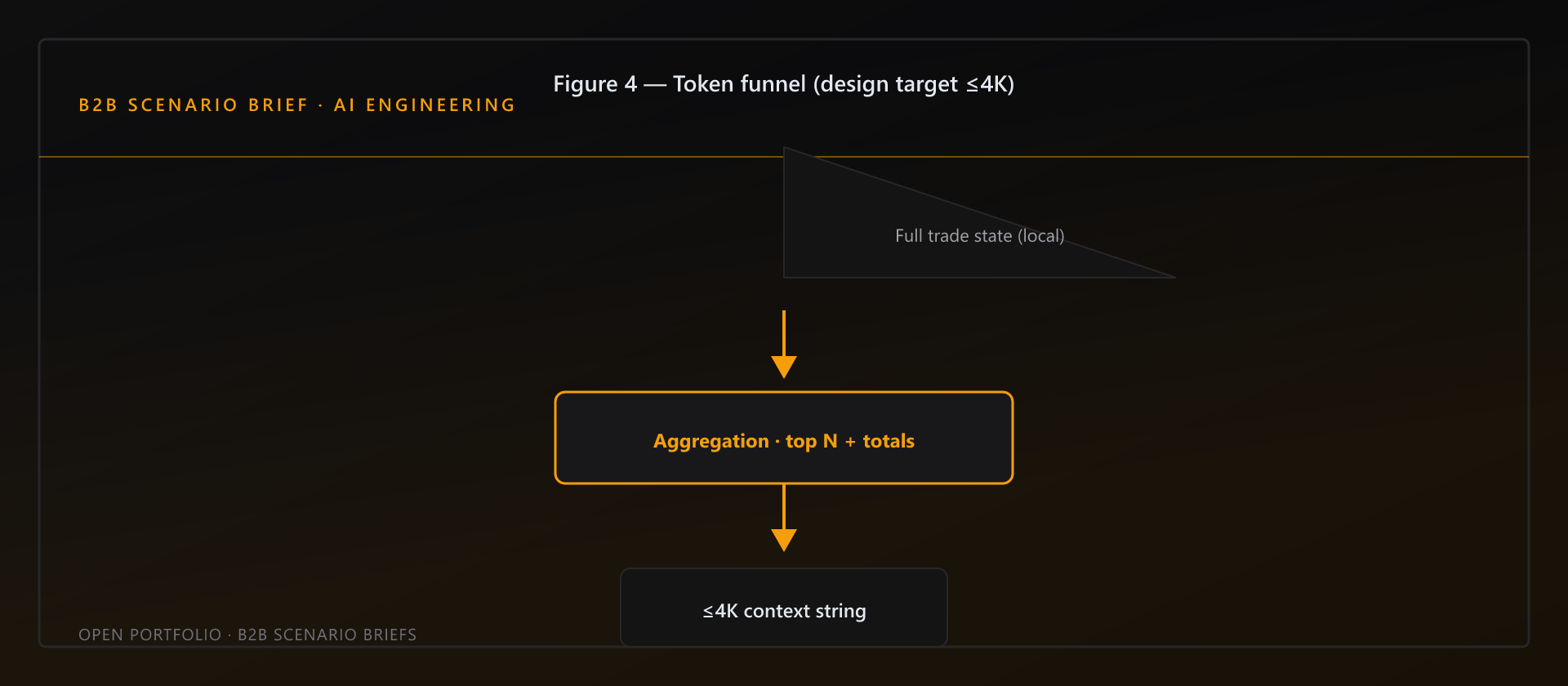
Figure 4 — Token funnel. Design target ≤4K tokens. Signal preserved; vector ledger on the inference path avoided.
Why Vector Databases Create Unnecessary Compliance Surfaces
Common RAG stack for portfolio Q&A:
- Ingest full history into PostgreSQL or a data lake.
- Chunk and embed transactions or holdings into Pinecone / pgvector.
- Retrieve wide context windows for each question.
- Log prompts for "quality monitoring."
Each step adds retention, re-identification risk, and subprocessor scope. InfoSec asks: Why does the model vendor's retrieval layer need ten years of buys and sells when the user asked about sector allocation today?
For regulated wealth, the alternative is not "no RAG." It is bounded retrieval by construction—aggregate first, embed never (for the default path).
The Mechanics of a Forgetful AI Session
End-to-end flow in the designed Open Portfolio boundary:
- Trades live locally — IndexedDB / client state on the harness; enterprise pilots scope your store.
buildPortfolioContext()runs client-side — pure function overTrade[]; outputs totals + top 10 holdings.POST /api/ai/chat— receivesmessage+context+ optional attachment; builds prompt; streams via Vercel AI SDK.- No portfolio write — route comment and implementation: payload used only for the LLM prompt; no database write or cache of the payload; quota metadata only.
/**
* Stateless: request payload (message, context, attachedContent) is used only
* to build the LLM prompt and stream the response. No database write or cache
* of the payload; only analytics/quota metadata are persisted.
*/
The session is forgetful: the next question rebuilds context from local truth, not from a server-side memory of the prior ledger dump.
Pure Functions vs. State Persistence on the Inference Path
The context engine is intentionally boring engineering:
| Approach | Compliance surface | Signal quality |
|---|---|---|
| Vector index of all trades | High — second durable ledger | High recall, high risk |
| Regex redaction before send | Medium — fragile, audit skepticism | Unpredictable leaks |
Pure-function aggregate (buildPortfolioContext) | Low — structural exclusion | Sufficient for allocation / performance questions |
Token budget (design target): Sovereign Intelligence documentation caps portfolio context at roughly ≤4K tokens so system prompt, user message, and optional attachment fit comfortably. In practice, typical portfolios produce a few hundred words—well under that cap. This is a documented design target, not a hard TypeScript validator inside contextBuilder.ts today. If "last K trades" features ship later, they must truncate to stay under the cap.
Two pipelines, one boundary:
- Importer — CSV →
Trade[](client edge). - Context builder —
Trade[]→ semantic summary (~1–2KB) for the LLM.
Paid attachment flows are an explicit second boundary with frontend and server length caps—default Ask AI does not require them.
Frequently asked questions
Can forgetful sessions answer trade-level questions?
Default path optimizes allocation and performance questions over row replay. Trade-level detail stays local unless the product explicitly scopes a narrower feature with its own review.
Do you store prompts for model improvement?
Portfolio context is not persisted server-side for inference as designed. Telemetry records tier, provider, and status—not a prompt archive of the ledger.
How does this compare to fine-tuning on client data?
Fine-tuning on itemized ledgers is the highest-risk pattern for wealth. Bounded aggregates + stateless inference keep training data out of scope for the default product path.
Where is the full technical blueprint?
Sovereign Intelligence book · Serial 03 — Edge Compiler.
Next steps: Architecture · Tier-1 design partner · Sovereign Engineering Serial 01 · Serial 03